Hunyuan AI vs Seedance 2.0: Which Image-to-Video Model Is Better in 2026?

Image-to-video generation is quickly becoming one of the most practical areas of generative AI. Instead of generating an entire scene from text, these models take a reference image and bring it to life with motion, making them especially useful for ads, character animation, and short-form content.
Two models gaining traction in this space are Hunyuan AI and Seedance 2.0. Both support image-to-video workflows, but they approach motion, consistency, and control very differently. That difference becomes important when choosing a model for real production use rather than simple experimentation.
In this comparison, we evaluate Hunyuan AI vs Seedance 2.0 across key criteria including prompt adherence, motion realism, temporal consistency, and artifacts. The goal is to determine which model is better suited for reliable image-to-video generation in 2026.
What is Hunyuan?
Hunyuan AI is part of Tencent's AI ecosystem and supports image-to-video generation by turning a reference image into an animated sequence. The model focuses on producing more dynamic motion, including camera movement, subject animation, and lighting changes.
One of its main strengths is visual intensity. Compared to other more controlled models, Hunyuan tends to give out a more cinematic and expressive output. Especially with well written/structured Hunyuan video prompts.
However, the tradeoff is that Hunyuan Img2Vid outputs may appear inconsistent in fine details and lack stability across frames. A problem that appears more prominent in complex scenes. While Hunyuan API can produce impressive results, achieving quality output often depends on prompt control and its tuning.
What Is Seedance 2.0?
Seedance 2.0 is a video generation model from ByteDance's Dreamina ecosystem that also supports image-to-video workflows. It focuses on animating reference images with smoother motion and more controlled scene development.
The main strength of Seedance 2.0 is consistency. Compared to more dynamic models, it preserves structure better across frames, resulting in cleaner and more stable outputs. This makes it well suited for production use cases where reliability matters more than aggressive motion.
Through the Seedance API, the model can be integrated into scalable workflows, and it is often preferred when predictable results and lower artifact rates are a priority. While the motion may feel more restrained, the overall output is typically more controlled and dependable.
Prompting
Prompt design plays an important role in image-to-video generation, especially when controlling motion, camera behavior, and scene consistency. While both models respond to structured prompts, their behavior can differ depending on how motion and detail are described.
Hunyuan generally benefits from prompts that clearly define movement, camera direction, and environmental changes to guide its more dynamic generation style. Seedance 2.0, on the other hand, performs better with more controlled and structured prompts that emphasize stability and gradual motion.
For more detailed guidance, you may refer to:
best prompt practices for hunyuan
best prompt practices for seedance
Pricing
Both Hunyuan AI and Seedance 2.0 are accessible through API-based pricing models, where costs vary depending on the generation type, resolution, and processing steps.
Seedance 2.0 offers multiple generation options, including standard text-to-video, faster variants, and image-to-video modes such as concat and replace. This gives users flexibility to balance speed, quality, and cost depending on their workflow. Seedance 2.0 price table is attached as follows
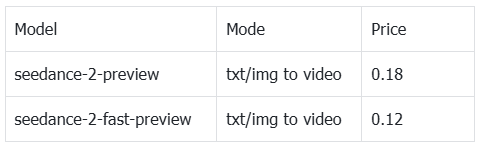
Hunyuan API pricing follows a similar usage-based structure, with costs tied to video generation settings and output complexity. In practice, pricing for both models is competitive, making them viable for scalable image-to-video production depending on performance needs. Hunyuan pricing is attached as follows
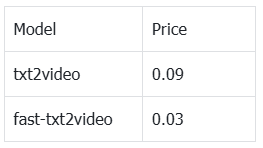
For more details you may refer to the following:
1. Hunyuan API Docs
2. Seedance API Docs
Evaluation Framework
Both models are evaluated using the same input and prompt to ensure a fair comparison.
We focus on four key areas: prompt adherence, motion realism, temporal consistency, and artifacts. This helps highlight not just visual quality, but how reliable each model is for real image-to-video workflows.
Example Comparisons
To evaluate Hunyuan AI vs Seedance 2.0 in real image-to-video scenarios, we tested both models using the same input image and prompt for each case. These examples focus on common use cases such as portrait animation, product visualization, and cinematic scene motion.
Example 1: Portrait Animation
Prompt:
A close-up portrait of a young woman, soft natural lighting, she slowly turns her head and blinks, subtle facial expression change, cinematic depth of field
Hunyuan Output
Seedance Output
Evaluation
Both models follow the prompt well, producing a close-up portrait with head movement and blinking. The difference shows in realism.
Hunyuan delivers smooth motion and strong consistency, but the lighting feels more artificial and the skin appears overly smoothed, giving a slightly synthetic look.
Seedance 2.0 produces a more natural result, with realistic lighting, subtle facial expressions, and better skin texture.
Overall, Seedance 2.0 stands out for stronger photorealism.
Example 2: Product Visualization
Prompt:
A premium mechanical wristwatch on a dark reflective surface, soft studio lighting, the camera slowly rotates around the watch, metallic reflections shift naturally, shallow depth of field
Hunyuan Output
Seedance Output
Evaluation:
Both models generate a premium watch with correct setup and camera movement, but differ in stability.
Hunyuan starts strong but struggles during motion, with watch details warping and losing structure as the camera rotates.
Seedance 2.0 remains stable throughout, keeping fine details intact while maintaining realistic reflections.
Overall, Seedance 2.0 performs better for product-focused use cases.
Example 3: Complex Scene Motion
Prompt:
A busy night street market in Tokyo, neon signs glowing, light rain falling, puddles reflecting colorful lights, people walking through the scene, camera slowly pushes forward, cinematic depth of field
Hunyuan Output
Seedance Output
Evaluation
Both models capture the overall night market scene with neon lighting, rain, and crowd movement, but differ significantly in realism and stability.
Hunyuan captures the general atmosphere but struggles with accuracy and motion. Pedestrians appear to slide rather than walk naturally, and as the camera moves forward, faces and background elements begin to warp and lose structure.
Seedance 2.0 delivers a much more realistic result. The environment feels coherent, with accurate signage, stable geometry, and natural pedestrian movement. Reflections and lighting behave consistently, even with multiple moving elements in the scene.
Overall, Seedance 2.0 handles complex scenes far better, maintaining stability and realism under more challenging conditions.
Conclusion
Hunyuan AI and Seedance 2.0 both deliver capable image-to-video generation, but they perform differently depending on the use case.
Hunyuan stands out for generating more dynamic and visually expressive motion, making it suitable for creative or cinematic outputs. However, this often comes with tradeoffs in consistency and structural stability, especially in more complex scenes.
Seedance 2.0, on the other hand, is more reliable across all test cases. It consistently produces stable, realistic outputs with better lighting, cleaner motion, and fewer artifacts. This makes it a stronger choice for production workflows where quality and predictability matter.
Overall, while Hunyuan shows strong potential, Seedance 2.0 is the better option for most real-world image-to-video applications in 2026.
Start testing both models and get your Seedance 2.0 and Hunyuan API keys via PiAPI today!
Unlock the power of 20+ AI models with PiAPI — image, video, chat, music, and more. Sign up today and start building smarter, faster and at scale.

