Cost effective, open source, powerful LLM DeepSeek API
Integrate the first generation of reasoning model API for DeepSeek with the R1 (671B) model! Power your LLM tasks with the most cost-efficient inference framework and infrastructure from PiAPI!
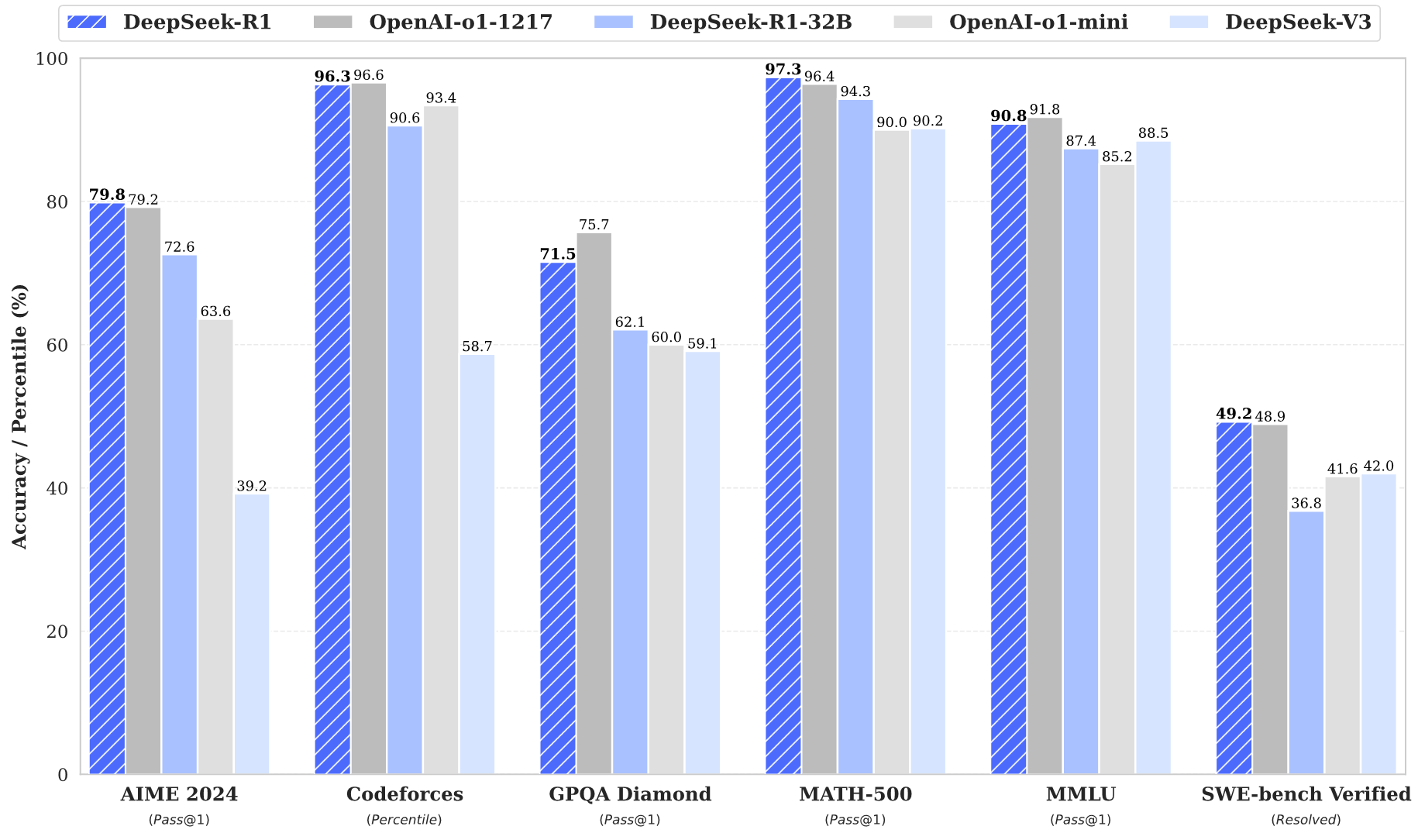
About our DeepSeek R1 API!
- Cost Effective.
- With superior inference infrastructure, we are able to provide extremely cost competitive API service for DeepSeek R1 model!
- Adequate Token Throughput.
- We work hard to keep our output token per seconds (TPS) level of 6 words per second for our users and their applications!
- Reinforcement Learning.
- R1-Zero demonstrates chain-of-thought (CoT) purely through reinforcement learning (RL), without relying on supervised fine-tuning (SFT).
- Multi-Stage Training with Cold Start Data.
- DeepSeek incorporates cold-start data to fine-tune the base model, with reasoning-oriented RL, rejection sampling, and supervised fine-tuning, achieving performance comparable to OpenAI-o1-1217.
- Distillation for Smaller Models.
- DeepSeek enables the distillation of reasoning capabilities into smaller dense models. By fine-tuning open source models like Qwen and Llama with the 800k samples from R1.
- Strong Performance across Diverse Tasks.
- R1 scores 79.8% Pass@1 on AIME 2024, and 97.3% on MATH - 500, on par with OpenAI-o1-1217. It also excels in coding-related tasks, achieving a high rating on Codeforces, and in other tasks such as creative writing, general question answering, and long - context understanding
- Easy Setup and Integration.
- Integrating our API is a hassle-free setup process with simple HTTPs calls, making it easy to integrate within any tech stack.
- Webhook.
- We will notify you of a completed task through our webhook feature, to avoid repeated fetch calls made through the network.
Pricing
Competitive Unit Pricing Based on Innovative Inference Infrastructure!
Model: DeepSeek-Chat 1 | Pricing
- $0.30 per 1M Input Tokens
- $1.8 per 1M Output Tokens 4
- Context Length: 64K
- Maximum CoT Token2: N/A
- Maximum Output Token3: 8K
Model: DeepSeek-Reasoner 1 | Pricing
- $0.60 per 1M Input Tokens
- $3.6 per 1M Output Tokens 4
- Context Length: 64K
- Maximum CoT Token2: 32K
- Maximum Output Token3: 8K
(1) The DeepSeek-chat model points to the DeepSeek-V3 model.The DeepSeek-Reasoner model points to the new DeepSeek-R1 model.
(2) CoT (Chain of Thought) is the reasoning content that DeepSeek-Reasoner provides before outputting the final answer.
(3) If the max_tokens is not specified, then the default maximum output length is 4K. Please adjust max_tokens to support longer outputs.
(4) The output token count of DeepSeek-Reasoner includes all tokens from CoT and the final answer, and they are priced equally.
(5) For detailed advanced API doc please refer to https://api-docs.deepseek.com/guides/reasoning_model.
Frequently asked questions
- What is PiPAI's DeepSeek API?
Our DeepSeek API is provided on PiAPI's custom AI inference framework and infrastructure, which allows developers to integrate the advanced, cost-effective LLM capability Chat and Reasoning from R1 and V3 into their own apps or platforms!
- Who is the intended user for the DeepSeek API?
The DeepSeek API is created for developers who want to incorporate state of the art language and reasoning capabilities into their generative AI applications. This feature is ideal for any AI powered coding assistants, literature review, documentation summary, translation applications, marketing and advertising related applications.
- How to get started with integrating the API?
After registering for an account on PiAPI, you will get some free credits to try the API. Using your own API-KEY you can start making HTTPs calls to the API!
- How do I make calls to the API?
You can call our API using HTTPS Post and Get methods from within your application. A wide range of programming languages that support HTTP methods (ex. Python, JavaScript, Ruby, Java, etc.) can be used to make the call!
- Is there a limit to the total number of requests or concurrent number of requests I can make?
We will queue your concurrent jobs if the number of your concurrent jobs exceeds a certain threshold. In terms of total number of requests, you can make as many requests as your credit amount allows.
- How does the API handle errors?
Our API returns error codes and messages in the HTTP response to help identify the issue. Please refer to our documentation for more details.
- Can you provide dedicated deployment for this API?
Yes, absolutely! We provide custom solutions for clients with specialized requirements (ex. low latency, higher concurrency, fine-tuned DeepSeek models, etc), and we do provide cost-effective and performance-enhanced solutions for these LLM usecases!
- What is the license for the DeepSeek model?
The DeepSeek Models have a custom open-source license and it is permissible for commercial use for any lawful purpose. Developers do not need to register or apply with DeepSeek before using the open-source models. Developer can also develop derivative models and product applications based on the Models.
- What is the pricing options for the API?
We offer the API through a pay-as-you-use system, you can purchase credits on our Workspace and monitor the remaining credits. The per-use cost of the API is reflected on upper portion this page. Please note that the credits purchased do expire in 180 days after purchase.
- How do I pay for this API?
We have integrated Stripe in our payment system, which will allow payments to be made from most major credit card providers.
- Are there refunds?
No, we do not offer refunds. But when you first sign up for an account on PiAPI's Workspace, you will be given free credits to try our API before making payments!
- How can I get in touch with your team?
Please email us at support@piapi.ai - we'd love to talk more regarding our product offering!